Reinforcement Learning consists of an agent and an environment wherein the agent executes an action (or decision) and receives a scalar reward (extrinsic) from the environment for that action.
However, in many applications the reward is extremely sparse or not present alltogether. For example, the rewards in the robotics fetch environments in OpenAI Gym are sparse since the agent only receives a reward of +1 when the arm reaches the given goal position and 0 everywhere else. Another example is the game - Montezuma’s Revenge where the rewards are extremely sparse since to receive a reward, the agent has to execute a long string of optimal actions. The reward here being the key. For all other states, the agent receives no reward.
One solution to the sparse reward problem is simple. Use dense rewards. But how? Reward shaping to the rescue. But, reward shaping is a very hard task and requires complete knowledge of the environment and the optimal actions. Not really ‘artificial intelligence’ then.
Another solution/solutions are to augment the environment reward signal with an intrinsic reward, a reward generated by the agents understanding, or lack thereof, of the environment or it’s dynamics.
Curiosity is one of the reward signals that can serve as an intrinsic reward signal.
Curiosity - a strong desire to know or learn something.
Curiosity is simply discovering as many new states as possible. Technically, it could be understood as the error in an agent’s ability to predict the consequence of it’s own actions. The problem with this naieve formulation is the huge state space that we usually encounter. For example, if an agent just naievely compares to states (for example in terms of mean squared error), it could always be curious, even for very similar states because of the environmental changes. Suppose a natural environment which an agent is navigating around. When the agent takes an action, the state changes according to the action. However, there are many other phenomena such as wind, leaves blowing, clouds moving etc that also change but are not dependent on the agent’s action and do not affect the agent.
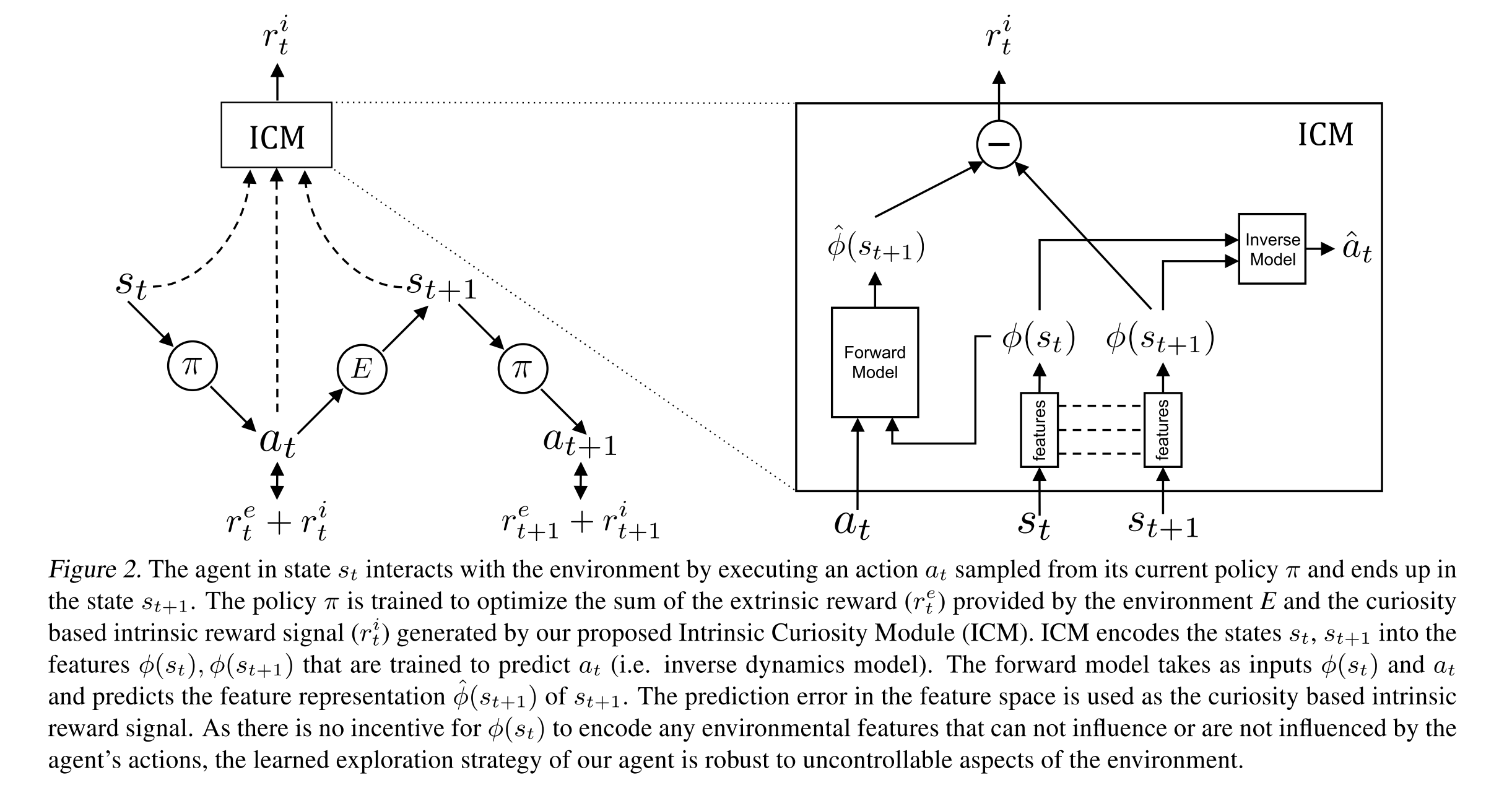
To counter this, the authors formulate “curiosity as the error in an agent’s ability to predict the consequence of its own actions in a visual feature space learned by a self-supervised inverse dynamics model.”
That is a mouthful. Let’s break it down.
Motivation
Suppose, you have an agent. In a traditional epsilon greedy exploration strategy, since the actions are completely random, we can reach previously visited states often and often get stuck. Now suppose you have a forward dynamics model i.e. a model that is able to predict the next state given the current state and action. What the paper states is that if you are uncertain about the next state that means that you would potentially “learn something new” by taking that action and therefore explore more. Therefore, the prediction error between the predicted next state and the real next state acts as the intrinsic reward provided to the agent.
Problem with pixel comparison
However, there is a problem with directly comparing visual states. The environment may have many entities which move around irrespective of the action executed by the agent. For example, the skull in Montezuma’s Revenge moves back and forth irrespective of the agent’s actions. If we were to naively compare the pixel predictions of the next predicted state and the actual next state, we could always label the next state as curious due to the changes in the environment.
Solution to the problem
The authors try to solve this problem by using an inverse dynamics model that transforms the raw sensory input to a feature space where only the information relevant to the action executed is represented. This way, the feature space will not contain any information about environmental changes.
How is this done ?
Simply by using an encoder like architecture that compresses the states into a feature space and then a fully connected network that takes these feature space vectors of the current state and the next state as input and tries to predict the action executed. This is called an inverse dynamics model since we are trying to predict the action from the states(inverse). This in turn ensures that the feature space only contains the relevant information.
Forward Dynamic Module
At training time, the state, action, next state tuple is collected. The state and the next state are passed through the encoder of the inverse dynamics module. The embedding of the current state and the action are provided to the forward dynamic module which then tries to predict the embedding of the next state. This is then compared to the actual embedding of the next state (Mean squared error) which acts as the loss for the forward dynamics module.
The entire module (Forward + Inverse Dynamics) is called the ICM or the Intrinsic Curiosity Module.
The forward dynamics module, the inverse dynamics module and the policy (A3C or PPO) are trained collectively.
Problems with Inverse Dynamics Module
- Since the policy, forward dynamics module and the inverse dynamics are trained on line, the learned features are not stable because the distribution changes as learning progresses.
- The features learned by the inverse dynamics module may not be sufficient since they do not represent important aspects of the environment that the agent cannot immediately affect
Alternative solutions to Inverse Dynamics Module
- Use Random Features.
- Use a variational autoencoder.
- Use an information maximizing variational autoencoder.
- Use stabilization tricks for the training the inverse dynamics and forward dynamics modules.
Why use Random Features?
- Simple solution which requires no extra training a resources. Basically, you just take the Encoder and fix the weights after a random initialization.
- Since the network is fixed, the features are stable.
- However, random features may not capture the important and relevant information of the environment.
Why use Variational Autoencoders?
- Features learned are low dimensional and may sufficiently capture the necessary information from the observations.
- The observations may contain irrelevant information. (Possibly use a beta-VAE ?)
- Unstable (similar to the inverse dynamics module).
The model used is described below
You can find the Pytorch implementation of the ICM Module at Pytorch-RL