Today we will discuss about a new research project/idea that I have been working on for the past couple of months.
This post will be quite long so …
TLDR: Combination of Stochasticity, task agnostic exploration and task based exploration measures greatly helps in sparse reward tasks.
Prologue
From the very beginning of my studies in machine learning, and specifically, reinforcement learning, I have been quite intrigued in the behaviour of agents in sparse reward tasks. Humans are extermely capable at exploring their environments and that too in an efficient manner. Having read about various exploration strategies such as curiosity, information theoretic approaches and count based exploration, the overarching theme that comes out is that most of these measures explore the environment quite well, agreed, albeit in a truly inefficient manner.
I like to think about exploration in two ways - task agnostic and task based and I find this is analogous to the types of Reinforcement Learning - Model based and Model free. Bear with me- Task agnostic measures such as curiosity continuosly explore the environment but do so without leveraging any prior information. They keep on exploring the environment in a somewhat trial and error fashion to find the all elusive reward(Sounds something like Model Free RL, right?).
Task based exploration, on the other hand, explore in the new task using the prior information the agent gained exploring in previous tasks. No crazy, expensive trial and error(Model based RL bells ringing).
But you know what, both the above measures are not perfect. Task agnostic measures are quite inefficent but can grab that reward that lies in that remote area of the environment. While task based measures are pretty efficient but they may ignore some really ‘hidden’ rewards.
Moreover, humans don’t really rely on just on of these ways to explore their environment. Often, they make use of a combination of both these measures to explore. And this is the motivation for the work that I am going to explain.
But first some discussion of the types of exploration explained above namely, Empowerment and MAESN.
Empowerment
Empowerment is basically the control an agent has over it’s future. More formally, it is defined as the channel capacity between actions and states that maximizes the influence of an agent on it’s near future or the mutual information between the action and the subsequent state acheived by that action.
For the work we will discuss about, we need to focus on a specific paper (Beautiful Paper by the way) that makes use of empowerment to enable a policy to learn various diverse skills, Diversity is all you need.
Diversity is all you need.
This paper closely follows prior work, Varitional Intrinsic Control, to learn complex, diverse skills that may or may not solve a given task. However unlike the VIC paper, they make a couple of important changes such as the use of a maximum entropy policy and a fixed skills distribution that greatly helps the policy to acquire useful , diverse skills.
The following are the primary components of their algorithm:
- Skills should dictate the state an agent visits.
- States should be used to distinguish between the various skills (and not states and actions).
- Those skills are learned that act as randomly as possible (Use a maximum entropy policy).
An overview of the algorithm presented in the paper:
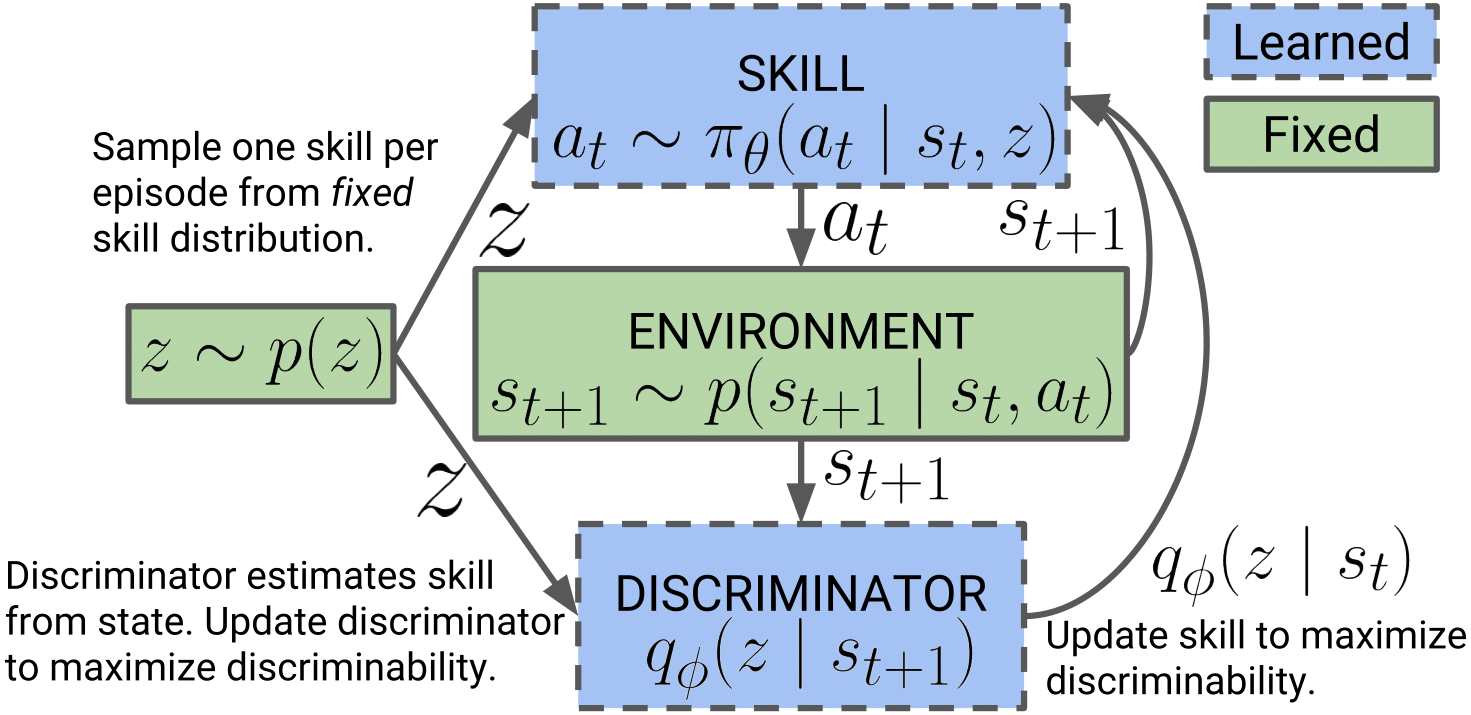
They were actually able to learn pretty useful and diverse skills and were able to achieve pretty decent results on various continuous control tasks.
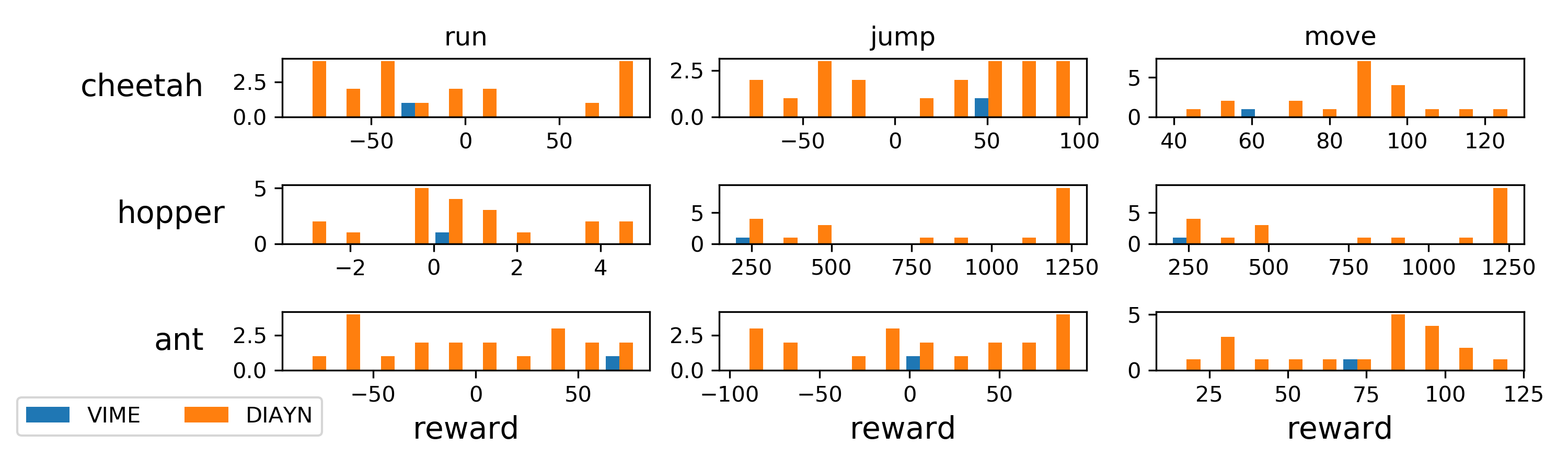
So far so good. Now we will take a look at task based exploration method, mainly MAESN or Model Agnostic Exploration with Structured Noise (That’s a mouthful).
MAESN
MAESN is based on gradient based meta learning. So we will first learn about Meta Learning and specifically, Model Agnostic Meta Learning (MAML).
Meta Learning - MAML
I have heard about supervised, unsupervised even reinforcement but what is this new form of sorcery ? Meta Learning is, simply put, learning to learn. Meta Learning intends to design models that can learn new skills or adapt to new environments rapidly with a few training examples. There are 2 main approaches to do this:
- Model based - Use a recurrent network
- Gradient based - Optimize the model parameters for fast adaptation.
Model agnostic meta learning comes under gradient based meta learning methods. If you want to learn more about meta learning, I would recommend this brilliant post - Meta Learning
Model Agnostic Meta Learning
Model agnostic meta learning draws inspiration from the success of transfer learning in Computer Vision. The intuition is that similar to how we train computer vision models on Imagenet and then finetune the layers on a new dataset, we can also learn the parameters of a model for many tasks from a given task distribution and then ‘finetune’ the model to a new task at test time.
More formally, assume you have a model f with parameters, theta. You are given a task t and the associated dataset. What MAML tries to do can be summarized in the following figure :
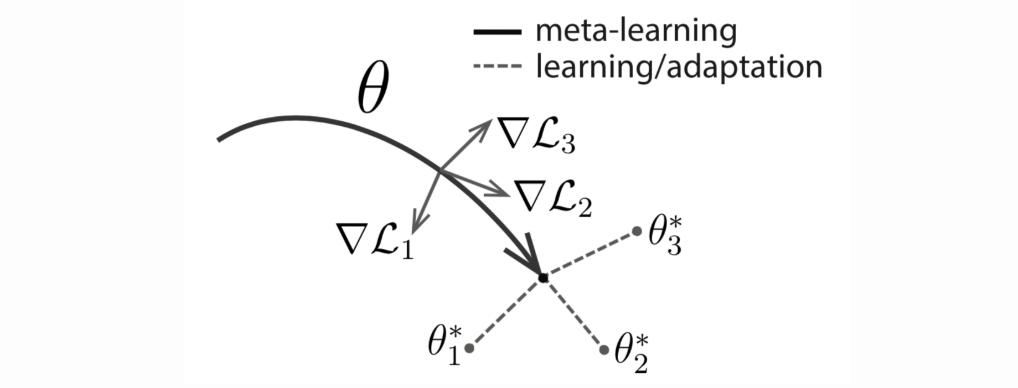
The final algorithm is the following :

The MAML objective for reinforcement learning is then:
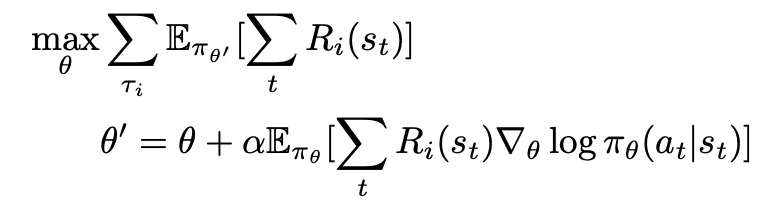
Why MAESN? What MAESN?
Standard Meta Learning/ Meta RL methods have been shown to be effective for fast adaptation problems in Reinforcement Learning however one problem that plagues these methods is the lack of any form of exploration. This hurts these algorithms in sparse reward tasks.
Tasks where discovering the goal requires exploration that is both stochastic and structured cannot be easily captured by such methods.
MAESN incorporates learned time-correlated noise by meta learning the latent space of the policy (it uses a latent variable policy), and trains both the latent exploration space and the policy parameters explicitly for fast adaptation.
Let us break these things down.
- Latent Space policies : Standard stochastic policies use an action distribution that is independent for each time step. Instead, latent space policies are conditioned on per-episode random variables drawn from a learned latent distribution.
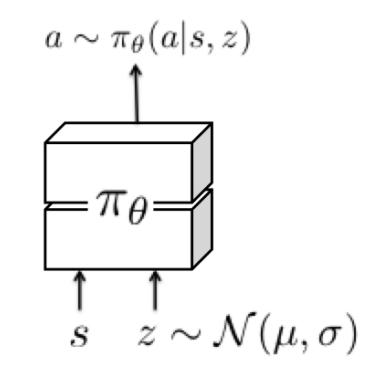
- Meta Learning Latent Variable Policies : A combination of variational inference and gradient based Meta Learning (MAML) is used for training the aforementioned latent space policies. Specifically, the aim is to train the policy parameters so that they can make use of the latent variables to explore effectively. Therefore, we learn a set of latent space distribution parameters for each task for optimal performance after a policy gradient adaptation step (MAML Adapt Step). This encourages the policy to actually make use of the latent variables for exploration.
For those woh require some math goodness, the full meta training problem :
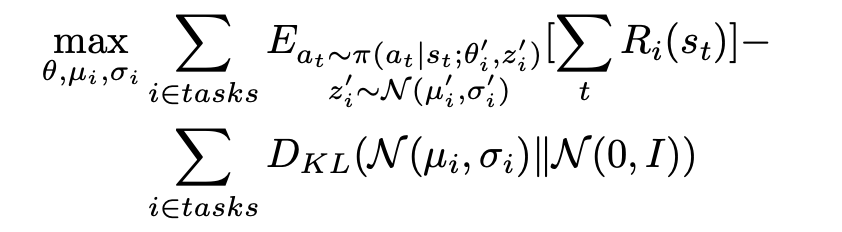
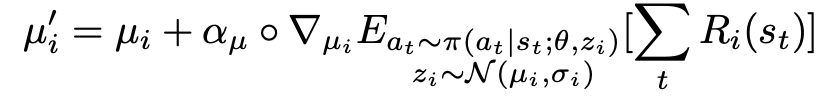
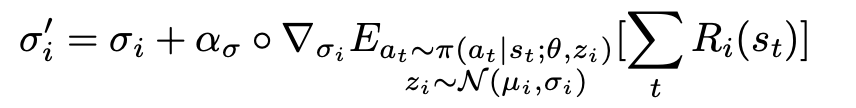
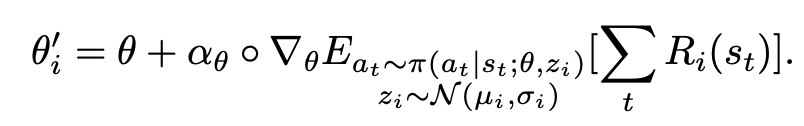
MAESN Algorithm

MAESN Results
MAESN is tested on a multitude of continuos control tasks but the one we would be focusing on for this post would be Robotic Manipulation.
Robotic Manipulation
The goal in Robotic Manipulation tasks is to push blocks to target locations with a robotic hand. In each task, several blocks are placed at random positions. Only one block (unknown to the agent) is relevant for each task, and that block must be moved to a goal location. Different tasks in the distribution require pushing different blocks from different positions and to different goals.
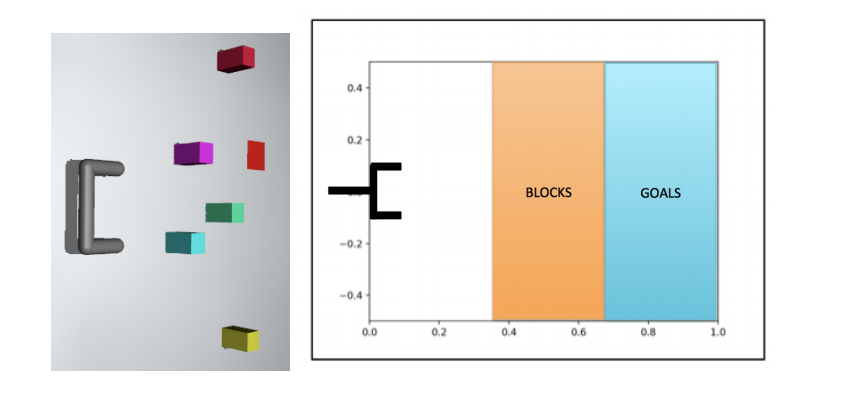
During metatraining, the reward function corresponds to the negative distance between the relevant block and the goal, but during meta-testing, only a sparse reward function for reaching the goal with the correct goal is provided. One thing to note here is that at meta training, a dense reward is provided to the agent instead of a sparse reward. Sparse reward is only used at meta testing time.